
Introduction
Software companies and consultants like to flex their Domain Driven Design (DDD) muscles by throwing around terms like Domain, Subdomain and Bounded Context. But what lies behind these buzzwords, and how these apply to customers' diverse environments and needs, are often not as clear. As it turns out it takes a collaborative effort between stakeholders and development team(s) over a longer period of time on a regular basis to get them right. And when you think you have figured them out, your models and concepts will get challenged by the ever-changing landscape of business requirements.
So why even bother with these fancy DDD terms? Why do we need them and how can we identify them? Aren't they just different contexts after all?
In this post we'd like to take you on a journey of riding the DDD roller coaster in the land of HR where paying back technical debt and diving deeper into the domain are everyday challenges.
Context and Abstraction
Classifying and categorizing things is in our human nature. We put things into boxes so we can reduce our cognitive load when we have to reason about things that belong to a certain box. We label these boxes with certain rules, concepts, and conventions that apply when we step into that box. Just like these boxes can help us reducing the aforementioned cognitive load, the abstraction they introduce might hurt us eventually when the environment in which they were formed changes. So let's treat a context as one of these boxes, a subset of the world with a certain amount of abstraction.
Initial Situation
During the last 4 years, we built a structured monolith that serves the following areas within the HR domain:
-
Employee records
-
Capturing various types of talks, conversations, and interviews between employee, superiors and HR like general feedbacks, personal notes, highly confidential notes, warning letters and terminations.
-
-
Employee Development Talks
-
Schedule, plan and record the annual development talk between employee and superiors (personal goals, personal skills assessment).
-
-
Employee search
-
Provides a general entry point to various usecases by making employees searchable through their “publicly” available information like name, department, working site
-
-
Demand management
-
Superiors claim employee demand and HR outlines a strategy to fullfill this demand.
-
-
Competence management
-
Align public image and self-image regarding competences. Record skill development over time.
-
-
Self Service
-
Allow employees to easily get in touch with HR in a more controlled way than per E-Mail as well as to directly access and edit information (like personal data, personalized application forms, etc) about themselves
-
From this point on our mental model consisted of several subdomains however we started questioning if they were really separated or do they share some common boundary. Do Employee Development Talks belong to a general record main domain or are they related to competence management and may belong to an Employee Development area? How should we even start?
Techniques to find subdomains
There are several tricks and heuristics you can apply in clustering features into subdomains.
-
Ask: what is the purpose of a feature? Do the features share the same goal?
-
Who is working on features? If same people work on features there may be an indication that they belong together
-
What are the domain terms for a feature? Do you use the same ubiquitous language for the features? If yes they may be close together and solve similar issues
-
Define problem statements for each subdomain. Does every feature of the subdomain adhere to this statement?
Bottom-Up Approach
As our mental model revolved around mainly low-level contexts, we gave the bottom-up approach a chance.
-
Start with the lowest feature level
-
Cluster and classify features based on similarities
-
Find a headline for the new higher-level domain
-
Define a problem statement
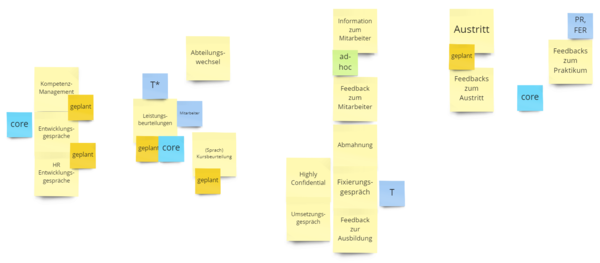
EXCERPT OF OUR FIRST CLUSTERING APPROACH
Besides the yellow features, you can see some classification post-its. Such as core or generic domain, are records written ad-hoc or in a planned meeting, who is affected by a feature, and who drives the feature. Using heuristics for classification will lead to different clustering. In the end, we had too many ideas and models in our brains. At this point, we were not able to agree on what the primary property of our boundaries should be. Is it the type of users, the confidentiality of data, or some temporal aspect?
We found out that we are all too deep into the way the domain is currently modeled and that we need someone with a fresh and distant view on this topic. So we “hired” a colleague from our consulting department to support us and moderate the workshops.

THE SAME CONCEPTS CAN BELONG TO DIFFERENT DOMAINS (1)
Top Down Approaches
As the bottom-up approach did not deliver a clear picture we agreed to advance our model from a top-down view. Let’s start with the top-level domain and divide it into smaller pieces. Generally, HR is not a customer-specific domain, each company has some kind of HR department and will face similar tasks to solve. The next reasonable step was to search for existing ideas for structuring an HR domain.
Ask the AI
Let’s have a look at how ChatGPT 3.5 will answer the question “How would you structure the HR domain in subdomains”
Answer (shortened)
-
Recruitment and Talent Acquisition
-
Employee Engagement and Retention
-
Performance Management
-
Compensation and Benefits
-
HR Operations
-
Learning and Development
-
Diversity, Equity, and Inclusion
Ask the Web
Additionally, we have found the following illustration in the literature that described Business Capabilities of the HR domain in general.

Our Version - Rework
Although these models were quite good we were skeptical to use them unreflected as is. However, they turned out to be good enough guidelines for our reworked model.
As the word employee kept coming up in different contexts, we decided to use it as our primary guidance in identifying our main categories. What does the customer mean by employee? Is it the same or is it different per context? As it turned out they mean quite different employee roles and that helped us shaping the boundaries around the possible sub-domains. At this point, it seemed obvious to integrate these different roles and their perspectives into our domain structure. After multiple iterations, the following final sub-domains were identified whereas some areas are not listed which are out of our product scope.
-
HR Strategie and planning
-
Organisation Development
-
Employee attraction and recruitment
-
Employee administration
-
Employee development
-
Relations
-
Analytics
Takeaways
Whether you follow a top-down or bottom-up approach can depend on which fits your domain better and the phase of your product/project is in. Trying out both as we did can also be a good path to take. It might be useful to evaluate existing models and validate them against your requirements. Clustering heuristics help you to get different views on your domain structure. It is preferred that you design more than one model and collaboratively work on the final outcome. Keep in mind that models will evolve over time. Continuous refinement is desired.
References
-
Domain, Subdomain, Bounded Context, Problem/Solution Space in DDD: Clearly Defined
-
Business Capability Map Example - Modeling Business Capabilities


















